이제 컴퓨터도 받고 대충 자리 정리가 끝나서 기념으로
집들이(?)를 한번 해 봅니다. ^.^ 대체로 다 선물 받은 것으로
가득차 있는 것이.. 역시 더불어 사는 인생입니다.;;;

오늘은 대전에도 눈이 무지 많이 왔어요~ 내일 눈싸움이라도
한 판 해야겠네요. 기대된당~ ^^
혜식이의 열고 보는 세상
이제 컴퓨터도 받고 대충 자리 정리가 끝나서 기념으로
집들이(?)를 한번 해 봅니다. ^.^ 대체로 다 선물 받은 것으로
가득차 있는 것이.. 역시 더불어 사는 인생입니다.;;;
오늘은 대전에도 눈이 무지 많이 왔어요~ 내일 눈싸움이라도
한 판 해야겠네요. 기대된당~ ^^
Brett의 소개글에서
ohloh에 대한 얘기는 처음 들었는데, 오픈소스 프로젝트에 관한
무지 재미있는 사이트를 발견했군요. +_+
예전에 FishEye 같은
프로젝트 소스 변화를 추적해 주는 곳이나,
Coverity같은
소스 품질을 검사해주는 곳은 봤었는데,
여기는 골고루 짬뽕인데다가 디자인도 예쁘고 아주 호감이 갑니다. 으흣. (물론 Coverity처럼 무결성을 검사하는 것은 아닙니다.)
파이썬에 대한 페이지에 가 보면, 주석의 양이나, 코드 크기에서 추산한 유지보수 비용과 소프트웨어의 자산가치, 라이선스의 특성과 잠재적 문제점 같은 것도 알려주고, 코드의 변화에 대해서도 시각적으로 아주 예쁘게 보여주네요~
뉴스를 수집해서 보여주는 것은 BerliOS에서도 했던 것과 비슷한 것 같은데, 그래도 요새는 RSS가 많이 쓰여서 손은 좀 덜 가긴 하겠네요.
CIA처럼 개발자별로 따로
통계를 내 주는 기능도 있는데, 이것도 CIA보다 예쁘게 나오는 것이.. 흐흐 아주 마음에 듭니다. 요새 몇달동안 전혀 커밋 안 한 게 들통나서 얼른 밀린 버그 목록을 좀 봐야겠습니다. –;
-ㅇ- (저는 cjkcodecs의 무식한 데이터 양 덕분에 변경한 라인 수로는 6위 -.-v =3=3)
요즘 리눅스 사용자들은 창 들고 흔들흔들 정도는 해 줘야
화면이 좀 뽀대가 나는 것 같아서, 부러움에 한번 큰맘 먹고
Beryl을 깔았습니다.
일단 Beryl을 쓰자면 Xorg를 포트에 없는 새 버전으로 올려야
한다기에, FreeBSD 위키에
있는 설명을 보고, 실험 중인 git 곳간에서 포트를 받아다가
설치했습니다. 포트 전체를 다 갖다놔서 생각보다는 편하더군요~
게다가 beryl도 포트로 만들어놔서 간단~ 🙂
결국 6시간의 빌드 끝에, xorg, gnome, beryl 모두 빌드하고,
nvidia 드라이버를 적당히 세팅해서 올려서 이런 화면이 짠!
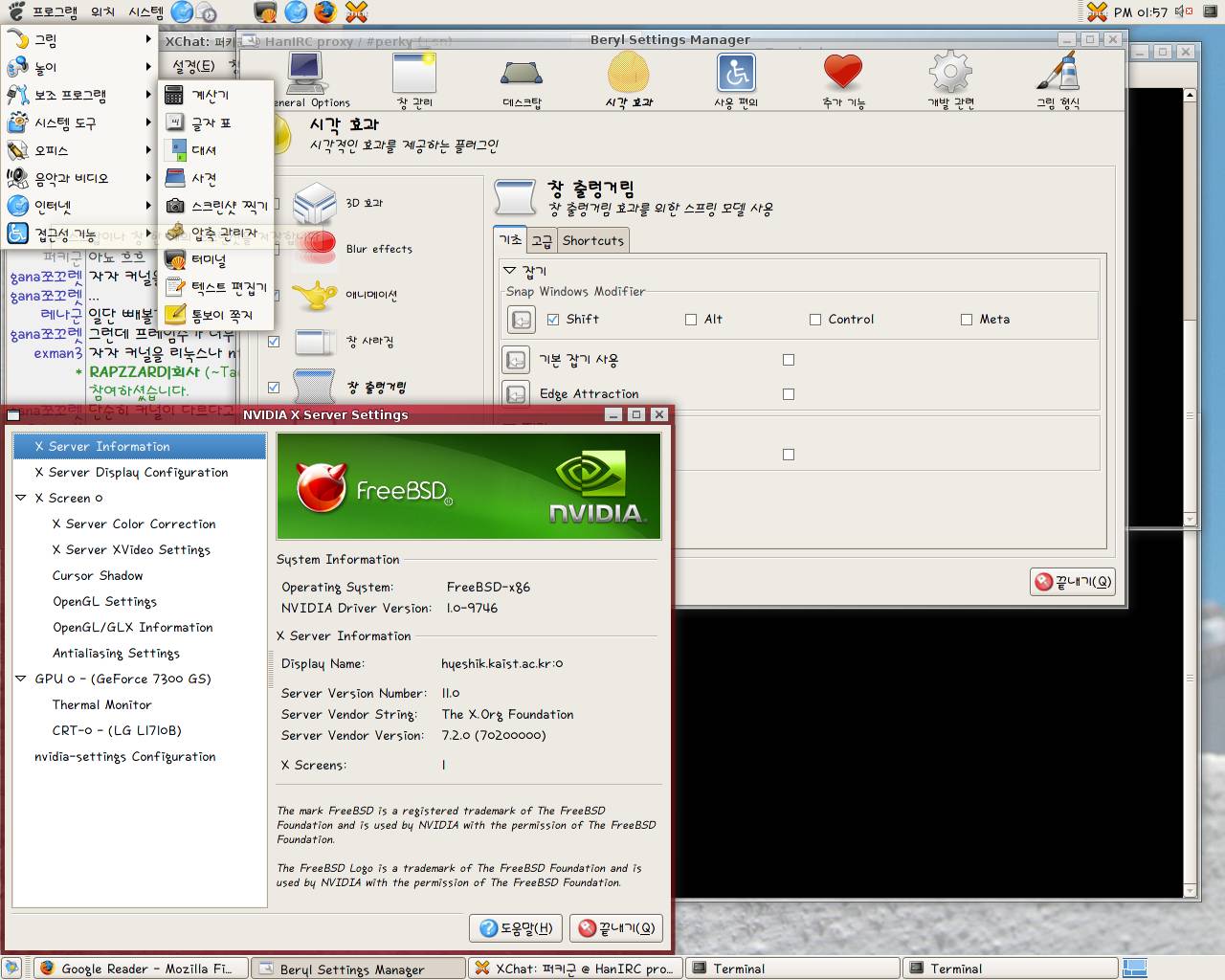
그러나.. 무엇이 문제인지, 클릭하면 거의 1분에 1프레임씩 지나가고 키보드로 우다다 쳐도 업데이트가 전혀 안 되다가 마우스 클릭 해 주면 그제야 10초 있다가 보여주고 그래서.. 눈물을 머금고 나왔습니다. CPU를 많이 쓰는 상태도 아니고, glx설정은 대체로 제대로 되어있는 것 같은데 이상하더군요..
혹시 투지가 있으신 분은 시도해 보시고, 성공하시면 방법을 알려주세요. +_+
==> 이후에 패치를 하나 추가해 주니까 멋지게 돌아다니네요 +_+ 와와~~~
제가 작년에 대학원 전공을 정한 이후 거의 만나시는 분들마다, 왜 열심히 하던
전산이 아니라 다른 걸로 하게 되었냐는 질문을 많이 하셨습니다. 사실 열심히 생각을
정리해서 정한 것이 아니라, 대충 엄부렁한 상태로 묘하게 끌려서 다가가게 되었는데,
여러차례 질문을 받으면서 답했던 것들을 생각나는대로 대충 모아서 글로 옮겨봅니다. ^_^
저는 현실적인 목표가 있는 것을 좋아합니다. 프로그램을 만들어도 가까운 사람이
무척 필요로 하거나 아니면 누가 칭찬해주거나 하다못해 저라도 잠시 필요해야 뭔가를
만들게 되더군용~ 그래서 지금까지를 생각해 보면 전산은 그 자체가 삶의 목적이었다기
보다는 주변 사람들에게 관심을 끌거나 칭찬받거나, 아니면 회사에서 붙어있기 위한
수단이었을 뿐이었다는 것을 느낍니다. 그래서 병역특례가 끝나가면서 전산을 오랫동안
계속 하려면 뭔가 새로운 목적이 필요하다는 생각에 허전한 마음이 많았습니다.
그리고, 사실 전산을 하다보면, 자기의 그런 목적을 자기가 정하는 것이 아니라 회사의 경영진이나
시대의 흐름, 커뮤니티의 환경에 따라서 결정이 되다보니, 정말 재미를 느끼는 목적이 아닌 것을
그래도 따라가야하는 경우도 생기고, 직접 결정한 것이 아니라 애착이 안 생기는 경우도 많고
그렇잖아요~ 예를 들어, 네트워크 전송 기술에 관심이 많아서 그쪽을 전공한다고 해도, 결국 사람들이 그걸로 뭐에 써먹을지는 모를 일이니, 시장의 눈치나 투자자의 눈치를 봐서 뭘 할지 결정해야 하고..
그런데 마침, 생물과 관련된 교양서를 여럿 읽고 있었기에, 결국 저도 그렇고 주변 사람도 그렇고
모두 사람이다 보니 누구나 생물에서 나오는 혜택을 직접적이거나 간접적이더라도 별로 멀지 않게
바로 느낄 수 있겠다는 생각과 소프트웨어만 해킹할 게 아니라 생명체도 해킹대상으로 좋지 않을까
하는 생각에 완전 매료되는 바람에 복학 뒤에 뒤늦게 생물 수업을 듣기 시작해서 결국 이렇게 되었습니다.
뭐 물론 새로 선택한 분야에서도 과정 중에 어쩔 수 없이 해야하는 내키지 않는 중간 단계가 없지는
않겠지만, 결국 적용되는 분야가 이제 70이 넘으셔서 귀도 잘 안 들리시는 외할아버지/할머니께도
“약 만들어서 사람들 치료하는 데 쓰이는 기술을 만들어요”라고 쉽게 설명할 수 있다는 점에서는
한동안은 열심히 노력할 수 있을 것만 같습니다. ^_^*
뒷이야기
실제로 그 대화는 이랬습니다. =.=;퍼키군: 약 만들어서 사람들 치료하는 데 쓰이는 기술을 만들어요.
외할아버지: 아~ 약만든다고?
퍼키군: 아니요. 약만드는 사람들을 도와주는 기술을 만들어요.
외할아버지: 아~ 약사발 같은 것 만드는거여?
퍼키군: (차마 더 설명은 포기;) 아아 네 ;;;;;
최근 PyCon과 Google TechTalk에서 귀도가 Python 3000에 대해 발표하였습니다.
Python 3000에 대한 것을 귀도가 모두 모아서 직접 소개한 것은 처음이라는 점에서
많은 사람들이 관심있게 지켜보았는데요, 동영상이 무려 1시간 30분짜리나 됩니다만,
금방 맛보실 수 있게 간단하게 요약해 봅니다. 그런데, 귀도가 최근에 무척 늙은 것 같더군요.
몇년 전부터 팀도 겉으로 보기에 급속도로 늙고 있어서 안타까움을 느끼고 있는데, 귀도도 이제
나이를 어쩔 수는 없네요.. 으흐..
파이썬 3.0은 언제 나올 것인가?
스펙을 규정하는 PEP(“펩”이라고 발음하더군요)은 2007년 4월까지, 첫 알파 버전은 2007년 6월,
2008년 6월에 최종 3.0 릴리스 예정이라고 합니다. 2.6은 2008년 4월을 예정하고 있고, 그 후로도
필요하면 2.7을 내놓을 예정입니다. 2.6은 주로 3.0으로 넘어가기 위한 여러가지 기능을 제공해 줄
예정이라고 합니다. 아마도 2와 3 모두를 지원하는 코드를
쉽게 작성할 수 있도록 몇가지 기능이 백포트될 것 같네요.
구식 클래스는 없다
2.1에서 들어왔던 new-style class가 이제 디폴트가 되어서, 구식 클래스가 사라지게 되었습니다.
둘의 차이를 직접적으로 항상 느끼는 분은 많지 않겠지만, 사용상 몇가지 연산자 정의나
상속 순위 같은 데서 차이가 납니다.
print가 이제 함수
종종 print 뒤에도 괄호를 쓰는 분들이 있긴 하지만, print는 그동안 statement였습니다. 이제부터
print도 abs나 sort같은 일반 내장 함수가 되었습니다. 그 말은, print뒤에 항상 괄호를 해야 한다는 것이고,
대략 보면 이렇습니다.
|
1 2 3 |
print x, y -> print(x, y) print x, -> print(x, end=" ") print >>f, x -> print(x, file=f) |
물론 대부분의 경우에 이걸 자동으로 번역해 주는 스크립트를 샤샥 돌리면 해결되지만, 한 가지 경우에 호환이 안 된다고 합니다.
|
1 |
print "x\n", "y" |
이런 경우 예전에는 y앞에 빈칸이 안 나왔지만, 앞으로는 y앞에도 빈칸이 들어간다는군요. 혹시 이것 원래부터 알고 계셨던 분도 있으시려나요? 파이썬에 이런 기능이 숨겨져 있는지는 저도 이번에 처음 알았습니다. -ㅇ-;
딕셔너리 뷰
예전의 토론에서는 딕셔너리의 items, keys, values가 모두 이터레이터를 리턴하도록 바뀌고, iter*는 없어진다고
얘기가 나왔었는데, 단순히 이터레이터를 리턴하는 것을 뛰어넘어서 새로운 타입을 리턴하도록 바뀐다고 합니다.
새로 리턴하는 것은 items와 keys의 경우 마치 set처럼 동작하는데, 원래처럼 내용을 보거나 훑을 수 있을
뿐만 아니라, 변경작업을 하면 원래의 딕셔너리에 반영도 할 수 있습니다. 반면에, values같은 경우에는
set처럼 변경작업을 하면 key로 뭘 넣을지가 모호하기 때문에, 그냥 읽기 전용이 된다고 합니다.
기본 비교 연산자의 동작 변화
이것도 많은 분들이 생각도 못했던 파이썬의 기능이 사라지는 것 같은데요, 파이썬에서는 그동안 객체의 기본
비교연산자가 모두 정의되어 있어서, 서로 다른 타입끼리도 말도 안 되는 비교가 가능했습니다. 예를 들어
dict와 list도 어느 놈이 크고 작은지 비교가 가능했고, 사용자가 정의한 클래스끼리도 비교가 됐죠.
(기준은 타입의 이름과 메모리 상의 주소랍니다. 으흐흐;;)
덕분에 서로 다른 타입이 잔뜩 들어있는 리스트도 정렬이 가능했었는데, 이제부터는 기본 비교연산자가
TypeError를 뱉게 했기 때문에, [“x”, 1].sort() 같은 것은 불가능하게 되었습니다. 일일이 정해줘야 합니다.
문자열이 유니코드로
이제 기본적으로 “”로 쓰는 str타입이 유니코드 기반으로 바뀌고, 기존의 8비트 옥텟의 연속열이 str에서 bytes라는
타입으로 바뀝니다. 이미 많은 분들이 이걸 듣고 긴장하고 계셨겠지만, 그 영향은 굉장한데, 이제 ASCII 파일을
읽어서 바로 대문자로 바꾸거나 그런 것은 불가능합니다. bytes는 bytes일 뿐 문자열이 아니므로 글자 취급도
안 하고, x가 bytes타입이라면 x[0]같은 인덱스는 str과는 달리 아스키 숫자를 리턴합니다. 아직 자세한 것은
많이 결정되지 않아서, 혹시 관심이 있으신 분들은 참여하실 여지가 있을 것 같네요.
유니코드기반 문자열로 바뀌는 것은 최근 추세를 따라가는 것이기도 하지만, 파이썬을 처음 배울 때
유니코드가 뭐고 문자열이 뭐고 일일이 변환을 손으로 해 줘야 해서 굉장히 겁을 주는데, 이걸 해결할
뿐만 아니라, 유니코드를 전혀 모르는 서구권 개발자들도 얼떨결에 국제화된 프로그램을 만들게 하는
계기가 될 것 같습니다.
파일 입출력의 변화
문자열이 유니코드가 됐기 때문에, 파일을 바이너리로 열 때와, 텍스트로 열 때가 달라야하는 상황이 왔습니다.
따라서, 바이너리로 열면 read()하면 bytes가 나오는 대신 readline같은 것은 불가능해지고 (bytes는 줄같은 것은
신경 안 쓰므로) 텍스트로 열면 str이 나오는 대신 인코딩을 지정해서 변환 과정을 중간에 거치게 된다고 합니다.
지금의 codecs.open를 생각하시면 되겠습니다~
int/long 통합과 나누기 연산
int/long이 원래 2.2에서 통합되어서 내부적으로 자동 변환이 되고 있지만, 이제 겉에서는 전혀 눈치챌 수 없도록
완전히 int 타입 하나로 통합한다고 합니다. 이제 long이란 없고 그냥 큰 숫자는 내부적으로 BigNum류 연산을
쓰고, 작은 숫자는 CPU의 숫자 타입을 씁니다.
그리고, 2.2였던가요? 그때부터 __future__를 통해 지원되었던, “true division”이 기본이 됩니다. 1/2해도 이제
0이 아니라 0.5가 되고 2/2해도 1이 아니라 1.0이 됩니다.
예외처리의 변화
그동안 많은 파이썬 개발자들을 괴롭혀 왔던 except E, v: 이게 드디어 exception E as v로 바뀝니다.
예외를 여러 개 잡으려고 exception E1, E2 썼다가 E2가 무시되는 바람에 멀쩡히 돌던 프로그램이
퇴근만 하면 죽는 낭패를 봤던 경험이 있는
개발자들이라면 모두 쌍수를 들고 환영할 것 같네요. ^.^
또한, v가 그동안 try except 블럭 스코프가 아니라 그 외부의 스코프에 속해서 지워지지 않아서
try-except가 반복되다보면 메모리가 모자랐던 끔찍한 혼란이 드디어 해결됩니다. except 블럭도
스코프를 만들어서 except 블럭이 끝나면 v가 사라지게 되었습니다.
인자 시그너처 표시
C++이나 자바에서 넘어온 프로그래머들이 그렇게도 원하던 기능! 함수 인자에 타입 선언해 주기
비슷한 것이 추가됩니다. 정확히 말하자면 타입 선언이 아니라 그냥 인자 이름 옆에 “”” 로 주석 쓰듯
뭔가 데이터를 넣어주는 것 뿐이고, 함수이름 밑의 속성으로 접근이 가능합니다. 이걸 활용해서
타입을 체크하거나 범위를 체크하는 데코레이터를 만들 수 있겠죠.
키워드만 받는 인자
그동안은 키워드 인자를 받도록 선언해 놓아도 왼쪽부터 순서대로 채워지기만 하면 키워드 인자까지
넘어와가지고 되는 경우가 있었는데, API 디자이너의 의도를 충분히 살려서 혼란을 없애고 싶은 경우를
위해, 키워드로만 받는다고 선언하는 문법이 생깁니다. 좀 문법이 희한한데,
|
1 |
def foo(a, b=1, *, c=42, d): … |
로 쓰면, c와 d는 키워드 인자로만 받는다는군요;;
집합(set) 표기법
2.4에서 추가되어 굉장한 인기를 끌고 있는 set이 드디어 소스에서도 간단하게 쓸 수 있게
표기법이 추가됩니다. {1, 2, 3}으로 쓰면 set이 된다고 합니다. 즉, :가 없으면 set, :가 있으면
dict가 되는 것이죠. set comprehension도 물론 생깁니다. 흐흐
|
1 |
{f(x) for x in S if P(x)} |
절대경로 임포트
파이썬 2.5에서 __future__로 숨겨져 있는 기능인데, 이제 패키지 경로의 혼란을 줄이기 위해서
패키지 내부에서 암묵적으로 상대적인 경로로 임포트가 가능하던 것이 금지됩니다. 이제 상대경로로
임포트를 하려면 . 이나 .으로 시작되는 다른 경로 이름을 써 줘야 하게 되었습니다.
문자열 포매팅
2.3인가에서 추가되었던 string.Template가 이제 표준 str타입의 % 연산자에서 지원되게 됩니다.
|
1 |
"See {0}, {1} and {foo}".format("A", "B", foo="C") |
여기서 하나 궁금해 지는 것은, string formatting에서 항상
나오는 복수형 만들기 문제나 조사처리 같은 것을 써드파티에서
추가할일이 생길텐데요. 그런 경우를 위해서 사용자가 타입별로
제어할 수 있게 하거나 훅을 넣을 수 있게 여러 기능을 제공할 것 같습니다.
새로운 scope 선언자 nonlocal
파이썬 2.1에서 nested scope가 들어오면서 무척 편해진 것은 사실이지만 그동안 global과 local
밖에 없어서 상위 스코프가 global이 아닌 경우 상위 스코프의 뭔가를 건드리려면 list로 만들어서
넣는다던지 편법을 써야 했습니다. 이걸 위해서 스코프 블럭 앞에 nonlocal이라고 선언하면
이쪽에서 쓸 것은 아니니 nested된 윗쪽 스코프 것을 건드려라 하게 됩니다. 말로 들으면 복잡한데
실제로 사용한 예를 보면 나쁘지 않군요. 🙂
|
1 2 3 4 5 6 7 |
def outer(): x = 42 def inner(): nonlocal x # <---- new print(x) x += 1 return inner |
switch/case ?
이 기능은 많은 사람들이 아주 옛날 1.4 시절부터 간절히 바라던 기능이고, 패치도 무척 많이 나왔는데,
결국 귀도가 PyCon에서 거수로 3.0에서도 안 넣겠다고 장난스럽게 결정했습니다. 흐흐. 아마도
귀도가 switch-case 싫어하는 것은 정말 오래전부터 일관적이었던 것이라서, 앞으로도 당분간은
들어갈 일은 없을 것 같네요. (파이썬에서 switch/case를 지원하는 것은 생각보다 많은 모호점을 만들어냅니다.
한 10분만 생각해 봐도 끔찍해서 그만 생각해야겠다고 덮어두게 되죠;)
그 외의 자잘한 변화
그 외의 주요한 변화
지금 거의 단일 단계로 쫙 펼쳐져 있는 라이브러리들이 Java나 .NET처럼 체계화된 모양을
어느정도는 갖추게 될 예정인데, 많은 사람들이 지금 토론중입니다. 그리고, C API도 변화되게
될 것이지만, 가장 큰 문제로 지금 많은 함수들이 char*을 받고 있는데, 문자열이 유니코드로
바뀌게 되어 버렸으니, 이걸 어떻게 적용할지 고민이 되게 될 것 같네요. 원칙은 함수를 추가하거나
지우기는 하겠지만, 원래 있던 함수나 API에서 인자 개수만 바꾸거나 타입만 바꾸는 일은
없을 것이라고 합니다. 이렇게 되면 컴파일러 에러로 대부분 다 깔끔하게 잡아낼 수 있겠죠.
오늘 파이썬 3000을 위해 할 수 있는 일
웬만한 것은 자동으로 변환할 수 있게 될 것이니, 걱정할 필요는 없고, 지금부터 짜는 소스는
파이썬 3000에 대비하여 호환성 있는 코드를 짜도록 노력해야 합니다.
기다릴 수 없어!
파이썬 3000 기다리기가 정말 괴로우시겠지만, 항간에 떠도는 “파이썬 3000도 펄6 꼴 날거야”
“파이썬팀이라고 별 수 있나 보나마나 계속 매번 6달씩 연기한다고 발표하다가 결국 5년 걸릴걸?”
이런 소문들은 거의 현실이 될 것 같지 않습니다. 귀도가 하겠다고 한 것은, 정말로 거의 금방
이룰 수 있는 것만 공약하고 있으며, 언제 끝날지 모르는 대공사는 최소한으로 줄여서 몇 개에
불과합니다. 정말 멋진 게 하나 나올 것 같지 않습니까? 매일 기다리기 지루하시면
달력에 2008년 6월까지 남은 날짜를 계산해서 X표시를 하면서 기다려 보세요. 🙂
더 관심이 있으신 분들을 위해 ==>
지난 번
파이썬 GIL 깊숙히! (상)을 쓴 이후로 그 글을 읽으신 분들의 느낌을
IRC, 오프라인, 블로그 등을 통해 많이 전해 들었습니다.
별 다른 코멘트 없이 사실을 전달하는 정도로만 써서 그랬는지, CPython의 구현에 굉장히 심각한
문제가 내재되어 있는 것처럼 느껴지고, 이것 때문에 파이썬에 크게 실망하신 분들도 있는 것 같습니다.
그렇지만, 파이썬의 GIL은 “문제”라기보다는, “특성” 정도가 훨씬 적당하지 않을까 싶습니다.
파이썬과 같은 높은 수준의 객체 추상화를 사용하는 언어는 필연적으로 객체들의 작업들을 내부적으로
구현하기 위해서 여러가지 lock 방법이 필요합니다. 프로그래밍 언어 뿐만 아니라, 사실 한정된 자원을
공유하는 운영체제, 플랫폼 시스템, 데이터베이스 등등 대부분의 프로그램이 그렇겠죠.
그런데, GIL은 lock을 구현하는 방법 중의 하나일 뿐입니다. GIL에 반대되는 fine-grained lock은
lock을 관리하는 부가적인 자료구조가 필요하고, lock이 세분화 되어있기 때문에 그에 따라 한 번 lock
하면 될 것을 여러 번 lock해서 작업해야하는 경우가 많이 생깁니다. lock 여러개를 왔다갔다 하느라 문맥 전환 오버헤드나 캐시 손실도 발생할 수 있고요. 또한, fine-grained lock은
데드락같은 상황을 해결하기 위한 방법을 추가로 사용해야합니다. 만약 운영체제의 디스크자원,
Bus I/O자원, 그래픽자원 등과 같이 종류도 다양하고 수도 많은 경우라면 당연히 서로 병렬로 작업이
효율적으로 일어나게 하려면 fine-grained lock을 사용해야 합니다. 그렇지만, 파이썬에서 필요한
lock은 대부분 CPU가 주요 자원으로 참여하는 것으로, 사실상 이전의 PC들이 대부분 CPU가 1개
였다는 점에서, GIL을 사용하는 것은 (1) 구현이 쉽고 (2) 프로그램이 효율적이고 (3) 구현의
복잡도가 낮아서 유지보수가 쉬우며 버그도 적게 해 줍니다.
CPython을 구현한 그룹은 기업 규모의 다른 팀들에 비해 상당히 작은 규모이며, 특히 플랫폼에 최적화된 복잡한 JIT와 객체 시스템을 구현한 뛰어난 VM을 Sun이나
MS같이 직접 제작하여 유지보수할
수 있을만한 크기가 전혀 아닙니다. 따라서, 한정된 개발자들이 파이썬 고유의 역량을 그의 특징을
살리는 데 투자하기 위해서는 복잡한 VM을 구현하는 것보다는, 새로운 라이브러리와 언어적 측면들을
발전시키는 것이 더욱 중요했고 그렇게 계속 발전되어 왔습니다. 또한, 이렇게 만들어진 파이썬 언어는
결국 IronPython이나 PyPy같은 더 높은 이상을 추구하는 프로젝트가 나올 수 있게 된 기반이 되었겠죠.
그리고, GIL을 “문제”로 보기 힘든 또 하나의 이유는, 운영체제나 데이터베이스같은 시스템과는 달리
파이썬은 프로그래밍 환경이기 때문에, 사용자가 GIL이 있다고 해도 더 좋은 방법들을 개발하여 쓸 수
있다는 것입니다. 사실 쓰레드 프로그래밍은 프로그램 안에서 여러 문맥을 쓰기 위한 좋은 방법 중의
하나이긴 하지만, 대부분의 경우에 쓰레드를 사용하는 부분을 멀티 프로세스로 처리하는 것도 가능하고,
그게 오히려 더 효율적인 경우가 많이 있습니다. 예를 들어, 과학 계산을 위한 프로그램을 CPU가 20개라서
쓰레드 20개로 돌리게 만들었다면, 이 경우 입력값과 출력값을 관할하는 한 프로세스와 다른 20개 프로세스가
서로 통신하게 분리해서 짜는 것도 가능하고 (통신 방법은 os.system 외에도 무궁무진), 아예 범용으로
코드 객체를 던져주면 그걸 실행해주는 서버를 20개 띄워놓는 방법도 있겠죠. 이렇게 되면, 쓰레드 20개로
띄우던 시절과는 달리, 꼭 컴퓨터 1대에서 다 돌아갈 필요가 없어지고 10개, 10개 나누거나 2개씩 10대로
나누는 등의 설정도 생각해 볼 수 있게 됩니다.
어떤 분들에게는 GIL은 현재 파이썬 구현의 최대약점이라고 보이실 수도 있지만, GIL 때문에 도저히 같이
못 살겠다 해도 그것을 기회로 삼아, 쓰레드 말고 다른 방법으로 구현하는 방법을 배워보시는
계기로 만들어 보시면 좋겠습니다. =3=3=3
예고대로 (하)편에서는 GIL을 다루는 (피해가는?) 여러 방법에 대해서 소개해 드리겠습니다. ^_^
잡지 같은 데서 유명한 사람들 인터뷰를 보면 “나를 만든 책” 이라면서 어릴 때
읽은 책 한 권이 큰 영향을 미쳤다고 소개하는 경우를 종종 봅니다. 근데, 저는
암만 생각해 봐도 어릴 때 책은 안 보고 맨날 오락이나 하고 놀아서 잘 생각이
나지 않았는데, 마침 이번에 이사하면서 대청소를 하다가 반가운 책을 하나 발견하고
자랑해 봅니다. ^_^;

91년에 친구가 5색 칼라 디스켓 경품을 준다는 말에 꼬여서 동네 컴퓨터학원에 간 후로
시키는 대로 잘 되는 것이 신기해서 이 책도 사고 저 책도 사고 했는데 이 책도
그 중의 하나입니다. 내용은 당시 컴퓨터 잡지에 늘 나오던 BASIC 언어 소스가
가득한 그냥 그런 내용인데, 소재로 게임이 대부분이긴 했지만, 장르도 다양하고
“수명 점치기”, “엘리자와 대화”, “성격 테스트”, “일정 관리” 같은 아주 간단한
여러 프로그램들이 있어서 100~200줄 정도만 열심히 치면 짠! 하고 책에 나왔던
프로그램이 진짜로 모니터에서 보였습니다. 감동~ =)

뭐 사실 이런 책이 알고리즘 같은 것을 배우는 데는 큰 도움은 안 되었겠지만,
코딩을 계속 재미로 할 수 있는 동기를 만들어주는 소재의 원천이 된 것이
큰 도움이 되지 않았나 합니다. 수명 점치기는 한글판으로 사전 찾아가며
번역하고 지문도 추가하고 UI도 만들고 해서 친구들한테 디스켓에 복사해 줘서
결과 파일 받아다가 통계도 내고 그랬었는데, 생활 속에서 늘 이런 저런 소품
프로그램을 만들어서 놀고 그런 것이 이때가 시작이었던 것 같네요. 으흐흐~

그 때 봤던 컴퓨터 잡지는 “학생과학” 이라고 하는 잡지 부록인 “컴퓨터랜드”를 봤는데요,
맨날 본권인 학생과학은 보지도 않고 던져놓고 컴퓨터랜드 뒤에 나오는 BASIC 소스만
사자마자 며칠 밤을 새서 치고 그거 고치면서 노느라 학교에서 43/50 등도 자주 해 보고.. 으흐흣 -ㅇ-;
위의 사진은 컴퓨터랜드에 응모해 본다고 만든 디스켓에 나름대로 장식이랍시고 디스켓 껍데기를
저렇게 만들었는데 –; 지금 보니 완전 유치하네요. ^^;; 당시에는 그래도 멋지다고 쓴 것 같은데;;;;;
디스크 레이블지에 보면 HELP를 HALP라고 커다랗게 써 놓았는데, 당시에 대구에서는 저걸 “암호”라는
전문용어로 불렀는데 그 뜻은 “실행파일명”이라지요. ^_^;;
요즘은 컴퓨터를 처음 시작할 때 일반적인 아이들이 배우는 과정에서는 조그만 장난감이
적은 편인데, 아무래도 앞으로 교육과정이 많이 발전하여 우리나라에서도 피코크리킷이나
비스킷 같은 재미있는 것들이 많이 도입 되었으면 좋겠습니다. 그렇지만, 당시에는 그래도
어른들이 평소에 쓰는 프로그램 비슷하게 아이들도 만들기가 쉬웠는데, 요즘은 거의 불가능하다는
점이 시간의 흐름이 아쉽긴 합니다.
9년동안 살았던 정들었던 신촌을 떠나서 대전으로 이사를 마쳤습니다.
하하 뭐 이사한다고 2달동안 글을 안 쓴 것은 아니고요, 왠지 손이 안 가서
-ㅇ-;;
대전 공기는 맑지만 기숙사 방은 문은 녹슬어있고 샤워실 타일은 온통 곰팡이에
장판은 너덜너덜 일어나려고 그러고 있긴 하지만.. 뭐 그래도 그나마도 없는 것보다는
낫다는 생각에 잘 적응해 보려고 마음 굳게 먹고 있습니다;;
23일에 입학하고 26일에 졸업하니 23~25일 간에는 학생^2인 셈입니다. 백수 생활도
못 하고 ㅡ.ㅜ;
이제 대전으로 터를 옮겼으니, 조만간 파이썬과 루비에 관한 세미나를 대전에서
한 번 해 볼까 생각중입니다. 얼마 전에 생물정보학S/W워크샵 2007
에서 루비를 사용했었는데, 루비도 상당히 재미있더군요. ^.^;;
그럼 조만간 대전에서 번개를 한 번~ 🙂
예전에 한 번 넣으려고 했다가 중간고사가 임박해서 그만뒀었는데, 오랜만에
libtomcrypt를 받아서 보니
드디어 RFC4269 SEED 지원이 들어갔습니다! 기말고사도 끝난 기념으로
재미 좀 보려고 했더니 이런 할 일이 없어서 아쉽게 되었네요;
libtomcrypt메인테이너인 Tom이 직접 구현해서 넣은 것 같네요
libtomcrypt는 작고 가벼운 구현 특성으로 인해 특히 엠베디드 환경에서
많이 사용되고 있는데, 이제 VPN기계들이나 공유기 같은 곳에서도 쉽게
SEED를 채용할 수 있게 되어서 잘 되었네요~ ^_^
이로써 이제 오픈소스 툴킷 중 SEED를 지원하는 것은
GNU libgcrypt
(GPL), Botan (BSD),
libtomcrypt (public domain)
세 가지가 되었습니다. 이제 이번 방학 때 FreeBSD와 Linux 커널에도
시간 날 때 한 번 밀어 넣도록 노력해 보겠습니다. ^_^
지난 8월의 대안언어축제에서는 Io 문법 발견하기를 했었는데요, 얼마 전의 오픈소스뛰어들기에서는 똑같은 포맷으로 Python 문법 발견하기를 진행해 보았습니다.
대부분의 참가자분들이 생소할 Io와 어느 정도는 익숙한 Python이 어떤 차이가 있을지 무척 궁금해서 참지 못하고 해버렸는데, 많은 분들이 참가해 주셔서 즐거운 경험이었습니다. ^^/
이번에는 똑같은 방법으로 2번 시행했고, 같은 자료로 똑같이 진행하려고 했음에도 불구하고, 첫번째와 두번째가 거의 중복된 주제가 없을만큼 완전히 다른 내용이 다뤄졌습니다. (진행한 사람이 이런 무책임한 -_-;) 사실 세션 내부에서는 대부분 참가자분들이 발견하신 것들과 질문을 위주로 진행했기 때문에, 참가자가 기존에 알고 있는 언어와 어떤 관점을 갖고 있느냐에 따라서 내용이 거의 눈감고 골프공 때리는 수준으로 결과가 달라지게 되는 것 같습니다.
첫 세션은 7분이 2,2,3명으로 조를 짜서 진행했는데, 10분 정도 지난 후부터 본격적으로 분위기가 달아올랐습니다. 첫 세션에 참가하신 분들은 C를 하시던 분들이 많았는지, 아무래도 제어구조나 자료형이 집중적으로 논의됐었습니다. 반면에 두 번째 세션에서는 자바를 하시던 분들이 많이 참여하셨는지, 객체적 성질을 자료에 거의 안 넣었음에도 불구하고 거기서 객체의 메쏘드 같은 것이 논의가 됐습니다. 두 번째 세션은 모두 12분이었고, 자리가 여의치가 않아서 4,4,4명으로 했던 것도 약간 변수로 작용한 것 같습니다.
지금까지 이런 형식으로 3번 진행해 오면서, 대부분 분들이 긍정적인 반응을 보여주시고 곧 익숙해서 능동적으로 참여하시는 것을 보고 앞으로 다른 곳에도 도입을 해 보면 재미있겠습니다. 다만, 부족한 점은 아무래도 실제로 코딩을 해보지 않고 차곡차곡 바닥부터 쌓아올리는 방식이 아니기 때문에, 약간은 사상누각이 되지 않나 우려가 있긴 합니다. 그래서, 적당히 보충하기 위해서는 1시간의 “발견”이후에 로제타카드 등을 이용해서 간단한 문제를 직접 페어로 해결하는 것이 바로 따라와줄 필요가 있을 것 같습니다.
그 외에도 몇 가지 아이디어를 생각해 보면, 각 페어들이 작업하는 것을 모두 스크린캐스트로 녹화한 다음, 화면에 동시에 2개 또는 4개를 배치한 다음에, 약간 빠른 속도로 플레이하면서 각 팀들의 의견이나 토론이 있으면 서로의 의견 차이와 잘 모르는 것을 안 수줍게 해결할 수 있는 자리가 되지 않을까 싶네요. 아무래도 생방송보다는 녹화방송이 편안하니까 ^.^;
기계공학의 최적화설계이론을 보면, 설계상의 몇가지 선택지가 있을 때 각각의 최적조건을 계산해서 유전자알고리즘을 사용하거나 동적계획법을 사용하여 여럿 중에서 계속 선택해 나갑니다. 튜토리얼에서 실습해 보는 간단한 프로그램에서도 이런 것들을 적용해서, 어떤 루프를 쓸 것인가, 어떤 자료형을 쓸 것인가 뭘 먼저할 것인가 이런 의사 선택을 모두 나열한 다음 (물론 작은 프로그램이니까 가능) 다른 페어들이 모두 각각을 경험해 보고 그 언어의 특성에서 어느 것이 더 좋았는지 얘기해 보는 것도 좋을 것 같구요~
다음에 좀 더 길게 해 볼 기회가 생기면, 해 보고 결과를 알려드리겠습니다. ^_^