평소에 IRC를 항상 켜놓고 생활하다보면 종종 굳이 시계를 보지 않아도 IRC에서 어떤 사람들이 떠들고 있는지만 봐도 대충 시간이 얼마쯤 되었겠구나 생각할 때가 있습니다. 창문과 가까이 자리가 있는 사람들은 밖에 사람들이 지나가는 방향만 봐도 대충 시간을 알 수 있고, 차가 많이 보이는 곳에 자리가 있는 사람들은 교통 상황을 봐도 대략 짐작할 수 있는 거나 마찬가지로요~
그래서, 과연 이게 그냥 기분탓인지 실제로 경향이 강해서 쓸만한 지표인지 시험해 보려고 지난 몇 개월간의 IRC로그를 분석해서 떠든 사람 이름(!)과 횟수를 가지고 시간을 1시간 단위로 추측하도록 한번 통계내어 보았습니다.
우선, 예측 방법은 요새 인기가 하늘을 날고 있는 random forest를 사용했는데,
R에 들어있는 randomForest 모듈을 사용하기로 했습니다. party 패키지가 좋다는 얘기도 있지만.. 매뉴얼이 허술해서 사용법을 터득하지 못한 관계로 –;;
데이터는 HanIRC의 #perky에서 우선 IRC 데이터를 1시간 단위로 각 닉네임 별로 대화한 횟수(줄 단위)를 해당 시간에 모든 사람이 말한 횟수에서 나눈 값을 뽑았는데, 이 방법으로 과열된 상황과 심심한 상황을 대략 평준화를 할 수 있을 것 같고.. 해당 시간의 입력 벡터에 해당 시간의 데이터 뿐만 아니라 이전, 이후 시간의 것도 넣어서 연속성으로 추측할 수 있게 했습니다. 그래서 총 20명의 데이터를 이전, 현재, 이후 3가지 해서 60개 + 전체 대화량 3개 해서 63개의 실수 벡터가 들어갔습니다.
채널에 참여하는 인원이 비정기적으로 들어오는 분들을 포함하면 200명이 넘기 때문에, 여기서 입력 샘플로 20명만 추려서 사용했습니다. 물론 그 기준은 어느 정도 생활 패턴이 일정하면서 대화량이 적지 않고, 대상 기간에 생활리듬이 급격하게 변할만한 사건이 없었던 것으로 추정되는 분들을 골랐지요. 🙂
그래서, 이제 간단한 스크립트(로그파서, 데이터 가공)로 데이터 가공을 끝내고 이제 R에서 읽어서 쭈욱 처리했습니다. 노트북에서 했는데도 그다지 오래 안 걸리네요. (트리 수는 디폴트가 500개)
|
|
irc <- read.table('traindata', header=TRUE) irc.rf <- randomForest(HR ~ ., data=irc, importance=TRUE, proximity=TRUE) pfile <- read.table('testdata', header=TRUE) pfile.pred <- predict(irc.rf, pfile) hist2d(as.numeric(pfile$HR), as.numeric(pfile.pred), nbins=24) |
3,5월 자료로 트레이닝해서, 4월 자료로 테스트를 해 보면 다음과 같은 예측값 히스토그램을 얻을 수 있었습니다.
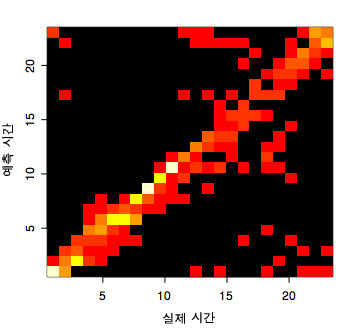
이것 보면 대략 오전은 거의 2시간 내외 오차로 썩 잘 맞히는 것 같고, 오후는 제법 오류가 많습니다. 특히 실제로는 늦은 오후 자료인데, 그걸 새벽 데이터로 오인한 경우가 많네요. 그리고 한낮 자료를 늦은 오후로 오인한 경우도 많고요. 역시 IRC사람들이 오전엔 아주 일정한 생활을 하는 반면에 오후에는 많이 바뀌는 것이 아닌가 싶군요!
각 시간에서 누가 얼마나 떠드는지가 더 의사 결정에 많은 기여를 했는지 알아보면 재미있을 것 같아서~ 그래프를 뽑아 봤더니 이렇게 나오는군요.

대충, 전체적으로 사람들이 얼마나 얘기하는가를 나타내는 prev, next, curr이 높고, 몇 명 평소에 상당히 규칙적인 생활을 하거나, 말을 많이 하는 분들이 상당히 점수가 높습니다. 시간별로 나눠서 보면, 새벽 0~6시 시간대에는 sakura님과 wooil님의 중요도가 아주 중요한데 패턴을 살펴보면 Sakura님이 말을 많이 하면서도 wooil님이 조용하면 새벽0~6시일 확률이 높다는 것을 알 수 있겠죠. 그리고 오전 9~10시 출근시간 무렵은 cocas님과 mithrandir님의 중요도가 높은데 일찍 일어나서 학교 가기전에 채팅하는 착실한 학생들(?)의 패턴이 아주 주효한 것 같습니다. -ㅇ-; 그리고 대략 저녁 6시 대의 중요도(variable importance)를 보면 퇴근시간이 일정한지 여부를 알 수 있을텐데요, 저녁 6시대에는 거의 높은 사람 없이 골고루 다 낮고, 정확도도 상당히 떨어지는 걸로 봐서는, IRC 사람들은 다들 불규칙한 저녁식사를 하는 모양입니다. -ㅇ-;
그 외의 또 다른 재미있는 지표로, outlier이라고 일반적인 패턴에서 벗어나는 샘플들을 골라내는 방법을 사용해서 상당히 평소와는 다르게 진행된 대화가 있나 한번 살펴보았는데, 3월과 5월에 대해서 outlier 지표를 그려보면 다음과 같이 나옵니다.
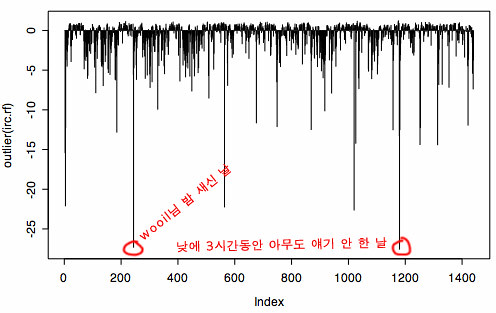
피크가 뚝뚝 떨어진 부분이 몇 군데 있는데, 이 부분이 평소와는 상당히 다른 일이 벌어진 경우를 의미합니다. 그래서 그 날짜를 구체적으로 로그를 살펴보면 정말로 평소하고는 아주 다른 일이 발생한 것을 알 수 있는데, 200주변(3월 12일)에는 평소에 밤에는 꼭 주무시는 wooil님이 새벽에 한참 대화를 하시는 이변이 발생한 날이고, 1200주변(5월 20일)에는 평소와는 달리 낮에 3시간동안 아무도 한 마디를 안 한 일이 발생했던 것입니다. 🙂
이제 대충 어느 정도는 정말 누가 말하는 지만 봐도 시간이 감이 오긴 한다는 것이 정량화가 되었는데요, 혹시 대화 패턴과 시간을 알면 요일도 알 수 있지 않을까 생각이 들었습니다. 그러니까.. 평소에는 낮에는 대화 잘 안 하다가 주말만 되면 S모 다방에 가셔서 하루 종일 IRC하시는 jachin님만 보면 일요일인지 당연히 알 수 있다던지 이런 것들도 정보가 되지 않을까 생각했는데, 의외로 통계를 내 보니까 거의 예측을 제대로 못하는게, 역시 IRC사람들은 주말과 평일 구분이 별로 없는 모양입니다;;
이 자료를 토대로 IRC 클라이언트 입력창 옆에 시계를 붙여 볼까 생각을 해 봤지만.. 너무 삽질같아서 포기.;; -ㅇ-;