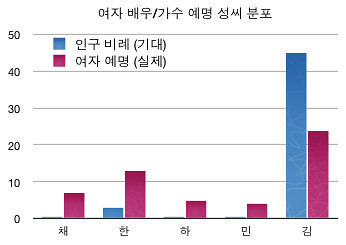
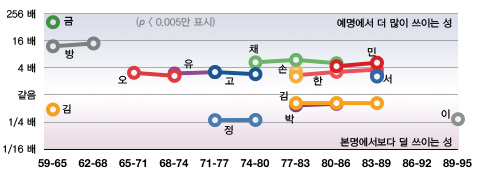
두 표본 집단의 차이가 의미가 있나 알아볼 때 보통
t-검정을 많이 씁니다.
t-검정에서는 값의 분포가 정규분포라는 가정이 있어서, 자료의
분포를 모르거나 정규분포로 바꾸기 매우 난감한 경우에는 t-검정을
할 수 없어서 비모수 검정을 사용하는데요, 이쪽으로 가장 인기있는
검정법은 아무래도 Mann-Whitney U test입니다.
어느날 MW-U로 재미나게~♪ 통계를 하다가~ 아니!! 결과가 엄청 편향되어 나오는 것입니다!
비모수라더니!! 마이크로RNA
마이크로어레이로 나온
결과를 분석하고 있었는데, 마이크로RNA가 염색체에서 떼로 몰려 있어서
한 놈이 올라오면 같이 우루루 올라오는 특성이 있다보니 군집이 엄청 큰
놈들에 의해 전체가 흔들려서, 아 무슨 좋은 방법이 없을까! 하다가
군집을 이룬 자료들에 쓸 수 있게 변형한 것
(Rosner and Grove, 1999,
Datta and Satten, 2005,
Haataja et al., 2009)
들을 발견했습니다. +_+
오…. 다 괜찮아 보이지만, 결국은 코드가 공개돼 있는
Datta와 Satten의 것으 로 해서 일단 결과를 뽑았습니다. 매우 만족스럽군요! ^_^
그런데 문제는 순수 R로 구현되어 있다보니
속도가 엄청나게 느려서, 자료가 별로 크지도 않은데 거의 2시간씩 돌려야
돼서 시험삼아 돌려볼 때도 마음을 크게 먹고 돌려야 해서, 바로바로
결과를 확인하는 재미가 없었습니다.
그래서 쭉 벼르고 있다가, 주말에 여자친구가 기말고사 공부해야 해서, 같이 공부하는
척 하느라 짬이 난 김에
C로 새로 코딩했습니다 (다운로드).
R이나 SciPy같은데서 쉽게 쓸 수 있게 외부 의존성을 없애려고, Z-통계치에서
p-value구하는 부분은 빼서 의존성을 줄였습니다. 그냥 libm만 있으면 됩니다.
(파이썬에서는 scipy.stats.norm.pdf를 써서 Z에서 p-value를 구할 수 있습니다.)
대략 돌려봤더니 2시간 걸리던게 30초로 줄었군요! 이히히 ^__^*
간단하게 컴파일한 다음에 파이썬에서 쓰려면 이렇게 쓸 수 있습니다~
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
<span class=“kn”>import</span> <span class=“nn”>ctypes</span>
<span class=“n”>cranksum</span> <span class=“o”>=</span> <span class=“n”>ctypes</span><span class=“o”>.</span><span class=“n”>cdll</span><span class=“o”>.</span><span class=“n”>LoadLibrary</span><span class=“p”>(</span><span class=“s”>'./cranksum.so'</span><span class=”p”>)</span>
<span class=“n”>crs</span> <span class=“o”>=</span> <span class=“n”>cranksum</span><span class=“o”>.</span><span class=“n”>clustered_rank_sum</span>
<span class=“n”>crs</span><span class=“o”>.</span><span class=“n”>restype</span> <span class=“o”>=</span> <span class=“n”>ctypes</span><span class=“o”>.</span><span class=“n”>POINTER</span><span class=“p”>(</span><span class=“n”>ctypes</span><span class=“o”>.</span><span class=“n”>c_double</span> <span class=“o”>*</span> <span class=“mf”>4</span><span class=“p”>)</span>
<span class=“n”>freecrs</span> <span class=“o”>=</span> <span class=“n”>cranksum</span><span class=“o”>.</span><span class=“n”>free_clustered_rank_sum_result</span>
<span class=“k”>def</span> <span class=“nf”>clustered_rank_sum</span><span class=“p”>(</span><span class=“n”>X</span><span class=“p”>,</span> <span class=“n”>grp</span><span class=“p”>,</span> <span class=“n”>cluster</span><span class=“p”>):</span>
<span class=“n”>N</span> <span class=“o”>=</span> <span class=“nb”>len</span><span class=“p”>(</span><span class=“n”>X</span><span class=“p”>)</span>
<span class=“n”>ret</span> <span class=“o”>=</span> <span class=“n”>crs</span><span class=“p”>((</span><span class=“n”>ctypes</span><span class=“o”>.</span><span class=“n”>c_double</span> <span class=“o”>*</span> <span class=“n”>N</span><span class=“p”>)(</span><span class=“o”>*</span><span class=“n”>X</span><span class=“p”>),</span> <span class=“p”>(</span><span class=“n”>ctypes</span><span class=“o”>.</span><span class=“n”>c_int</span> <span class=“o”>*</span> <span class=“n”>N</span><span class=“p”>)(</span><span class=“o”>*</span><span class=“n”>grp</span><span class=“p”>),</span>
<span class=“p”>(</span><span class=“n”>ctypes</span><span class=“o”>.</span><span class=“n”>c_int</span> <span class=“o”>*</span> <span class=“n”>N</span><span class=“p”>)(</span><span class=“o”>*</span><span class=“n”>cluster</span><span class=“p”>),</span> <span class=“n”>N</span><span class=“p”>)</span><span class=“o”>.</span><span class=“n”>contents</span>
<span class=“n”>r</span> <span class=“o”>=</span> <span class=“p”>{</span><span class=“s”>'S'</span><span class=”p”>:</span> <span class=”n”>ret</span><span class=”p”>[</span><span class=”mf”>0</span><span class=”p”>],</span> <span class=”s”>'E.S'</span><span class=”p”>:</span> <span class=”n”>ret</span><span class=”p”>[</span><span class=”mf”>1</span><span class=”p”>],</span> <span class=”s”>'Var.S'</span><span class=”p”>:</span> <span class=”n”>ret</span><span class=”p”>[</span><span class=”mf”>2</span><span class=”p”>],</span> <span class=”s”>'z.stat'</span><span class=”p”>:</span> <span class=”n”>ret</span><span class=”p”>[</span><span class=”mf”>3</span><span class=”p”>]}</span>
<span class=“n”>freecrs</span><span class=“p”>(</span><span class=“n”>ret</span><span class=“p”>)</span>
<span class=“k”>return</span> <span class=“n”>r</span>
<span class=“n”>X</span> <span class=“o”>=</span> <span class=“p”>[</span><span class=“mf”>1</span><span class=“p”>,</span><span class=“mf”>4</span><span class=“p”>,</span><span class=“mf”>2</span><span class=“p”>,</span><span class=“mf”>4</span><span class=“p”>,</span><span class=“mf”>6</span><span class=“p”>,</span><span class=“mf”>7</span><span class=“p”>,</span><span class=“mf”>4</span><span class=“p”>,</span><span class=“mf”>7</span><span class=“p”>,</span><span class=“mf”>8</span><span class=“p”>]</span>
<span class=“n”>grp</span> <span class=“o”>=</span> <span class=“p”>[</span><span class=“mf”>0</span><span class=“p”>,</span><span class=“mf”>1</span><span class=“p”>,</span><span class=“mf”>0</span><span class=“p”>,</span><span class=“mf”>0</span><span class=“p”>,</span><span class=“mf”>1</span><span class=“p”>,</span><span class=“mf”>1</span><span class=“p”>,</span><span class=“mf”>1</span><span class=“p”>,</span><span class=“mf”>0</span><span class=“p”>,</span><span class=“mf”>1</span><span class=“p”>]</span>
<span class=“n”>cluster</span> <span class=“o”>=</span> <span class=“p”>[</span><span class=“mf”>1</span><span class=“p”>,</span><span class=“mf”>1</span><span class=“p”>,</span><span class=“mf”>2</span><span class=“p”>,</span><span class=“mf”>2</span><span class=“p”>,</span><span class=“mf”>2</span><span class=“p”>,</span><span class=“mf”>2</span><span class=“p”>,</span><span class=“mf”>0</span><span class=“p”>,</span><span class=“mf”>0</span><span class=“p”>,</span><span class=“mf”>0</span><span class=“p”>]</span>
<span class=“n”>print</span> <span class=“n”>clustered_rank_sum</span><span class=“p”>(</span><span class=“n”>X</span><span class=“p”>,</span> <span class=“n”>grp</span><span class=“p”>,</span> <span class=“n”>cluster</span><span class=“p”>)</span>
|
으음.. R에 붙이는 것은… 아직 잘 몰라서… (나중에..;)