인터넷에서 글을 쓰다보면 “왠지 이 글에는 누구 누구가 댓글을 달겠구나.”하고 느낌이 강하게 올 때가 있습니다. 글 올리고 나서 열심히 10분마다 리프레시 하다가 (;;;) 누가 댓글을 딱 달면 “역시 낚였구나!” 하기도 하고.. -ㅇ-; 그렇다면 댓글을 누가 썼는지만 봐도 대략 글 내용을 추정할 수도 있지 않을까요? 그래서 오늘은 미투데이에서 댓글 쓴 친구 목록만 가지고 비슷한 글끼리 묶고 각 친구들의 성향을 분석해 봤습니다. (이제 점점 무슨 인터넷통계 블로그로 변신을 –;)
분석대상은 여러가지 요인들을 고려할 볼 겨를도 없이 그냥 한국 IT블로그계의 여왕벌 이지님의 최근 2달 글로 했습니다. ? (미리 이지님과 댓글을 쓰신 친구분들께 양해를 구하지 못한 점 죄송합니다~)
분석 과정
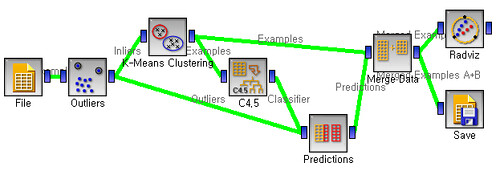
우선 가설은 “비슷한 글에는 비슷한 친구들이 댓글을 단다.”로 세웠습니다. 그 후의 분석과정은 생략하고 Orange의 플로우 그림으로 대체합니다. 최초 입력은 친구가 각각 해당 글에 댓글을 썼는지 여부를 0/1로 표시한 큰 행렬에서 몇 종류의 노이즈를 제거했습니다.
비슷한 댓글을 다는 친구 묶음
이렇게 해서 나온 결과로 각 친구들끼리 얼마나 비슷한 글에 댓글을 달고 있는지를 보여주는 다음 그림이 나왔습니다.
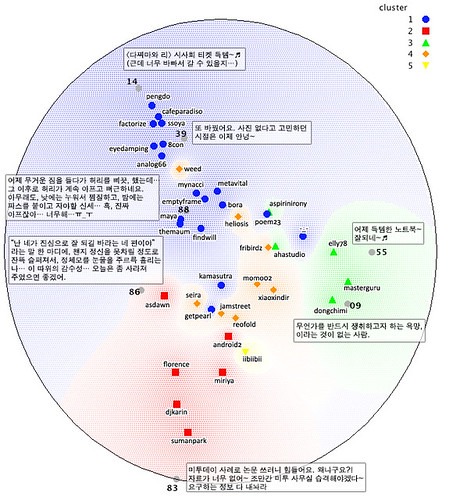
비슷한 경향의 친구들끼리 같은 클러스터(색깔)로 묶였는데, 파란색(1) 묶음은 다른 묶음에 비해 다양한 친구들이 묶여있고, 다른 묶음들은 각기 독특한 경향이 있습니다. 위 그림은 7가지 글에서 댓글을 달았는지 여부를 가지고 각 친구들 경향을 눈으로 잘 보이게 그림으로 그린 것인데요. 각 글(회색점, 글 내용은 흰색 네모)에 댓글을 쓴 경우에 점에 가깝게 표시되어 있습니다. 14, 39번 글에 파란색 친구들이 많이 몰려있고, 83번 글에는 빨간색 친구들이 많이 몰려 있습니다.
파란색 친구들은 대체로 누구나 쉽게 글을 달 수 있는 글에 댓글을 단 경우가 많았고요, 빨간색, 초록색 친구들은 각기 독특한 성향이 있었는데, 윗 그림에서는 잘 나타나지는 않았지만, 빨간색은 학술적인 글이 많이 포함되어 있었고, 초록색은 친한 친구들이 댓글을 달 만한 글들이 많았던 것 같네요.
비슷한 친구들이 댓글을 다는 글들의 묶음
실제 위에서 나타난 친구묶음들의 분포를 기준으로 다시 글의 분포를 구성해 보면
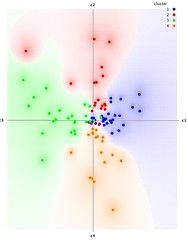
그림이 글을 표시하기는 좀 빽빽해서 각 친구묶음들이 선호하는 글의 대표적인 사례 몇 가지를 뽑으면 이렇습니다. (전체 텍스트 목록)
친구묶음 1(파란색)이 좋아하는 글
| 친구묶음1 | 친구묶음2 | 친구묶음3 | 친구묶음4 | 댓글수 | 내용 |
| 0.64 | 0.20 | 0.25 | 0.00 | 44 | <다찌마와 리> 시사회 티켓 득템~♬ (근데 너무 바빠서 갈 수 있을지…) |
| 0.43 | 0.20 | 0.00 | 0.00 | 87 | (삼계탕 말고) 보양식으로 무엇이 있나요?! 몸이 좀 허해진 것 같아서… 내일 좀 챙겨먹으려구요. |
| 0.36 | 0.20 | 0.00 | 0.00 | 27 | (집에서는 커피 금지령이 내린 관계로) 밤샘 작업을 위해 할 수 없이 커피를 사왔는데, 이렇게 맛이 없을 수가… 야식 배달 전문점 말고, 밤샘 커피 배달 전문점이 있다면 얼마나 좋을까… |
| 0.14 | 0.00 | 0.00 | 0.00 | 46 | 이제 미투사무실 왔어요~♥ |
친구묶음 2(빨간색)이 좋아하는 글
| 친구묶음1 | 친구묶음2 | 친구묶음3 | 친구묶음4 | 댓글수 | 내용 |
| 0.00 | 1.00 | 0.00 | 0.17 | 40 | 미투데이 사례로 논문 쓰려니 힘들어요. 왜냐구요?! 자료가 너무 없어~ 조만간 미투 사무실 습격해야겠다~ 요구하는 정보 다 내놔라! |
| 0.14 | 0.40 | 0.00 | 0.00 | 33 | 어떤 논문에서, “(…) frequent IM users tend to exchange shorter messages over a longer period of time, and they are more likely to engage in multitasking.” |
| 0.07 | 0.40 | 0.00 | 0.17 | 24 | 어떤 논문을 보니, dodgeball 창업자는 자사 서비스에 대해 “facilitating serendipity”라고 말했더라. 이 대목에서 난 너무 웃었다. 이쯤되면, 만박 님도 한말씀 하셔야죠? 미투에 커플이 몇인데! ^-^ |
| 0.07 | 0.40 | 0.25 | 0.00 | 21 | 한국언론재단의 2008년도 수용자 의식조사에 따르면, 매체 영향력 및 매체신뢰도 조사 결과가… 1위 KBS, 2위 MBC, 3위 NAVER라고. (오늘 각각 1위부터 10위까지 봤는데 좀 놀라웠어요. 조사를 어떻게 했는지…) |
친구묶음 3(초록색)이 좋아하는 글
| 친구묶음1 | 친구묶음2 | 친구묶음3 | 친구묶음4 | 댓글수 | 내용 |
| 0.14 | 0.00 | 0.75 | 0.17 | 48 | 어제 득템한 노트북~ 잘되네~♬ |
| 0.07 | 0.20 | 0.75 | 0.00 | 22 | 무언가를 반드시 쟁취하고자 하는 욕망, 이라는 것이 없는 사람. |
| 0.14 | 0.20 | 0.75 | 0.00 | 37 | A Grammar of the Multitude. 나에게는 이 책이 두 권 있다. 나머지 한 권으로 무엇을 하면 좋을까~?! |
| 0.07 | 0.00 | 0.50 | 0.00 | 9 | 시간은 왜 항상 부족할까… |
친구묶음 4(주황색)이 좋아하는 글
| 친구묶음1 | 친구묶음2 | 친구묶음3 | 친구묶음4 | 댓글수 | 내용 |
| 0.00 | 0.00 | 0.00 | 0.50 | 17 | 이 책을 편의점(!)에서 파는 것을 보고, “이 정도로 베스 트셀러야?!”하며 경악했던 적이 있는데. 정말 많이 팔렸구나. 울 엄마 말씀으로는, 외숙 모들도 다 읽으셨단다. (엄마도 요즘 읽고 계신다…) |
| 0.00 | 0.00 | 0.00 | 0.50 | 19 | 1976년 생인 이 책의 저자는 도쿄대학교 대학원 박사과정을 “수료 후 자퇴”했다. 꾸준히 논문과 저서를 발표하고 있고, 박사논문을 포기할 상황도 아니고, 후속 연구도 정했고, 다른 직장으로 외도한 적도 없고, 지도교수와의 관계도 좋은데… 왜?! |
| 0.57 | 0.00 | 0.50 | 0.83 | 68 | 2년 동안 함께 만든 책인데, <문화관광부 우수학술도서>로 선정되었어요!!! 글 쓰고, 편집하고, 섭외하고… 열심히 뛴 보람이 있구나~ㅠ_ㅜ ( “보람”이라는 단어는 이럴 때 쓰는 건가봐~) |
| 0.14 | 0.00 | 0.25 | 0.50 | 24 | 이 책의 원제는 [불안형 내셔널리즘의 시대]. 그런데 역서 제목이 이렇게 뽑혀버려서~ 마치 가벼운(!) 시사평론집처럼 느껴진다. (사실은 그렇지 않 은데~ 한번쯤 읽어봐도 괜찮은 책인데~ 주위에서 이 책 구입한 사람 나밖에 없어~ㅠ_ㅜ) |
각 친구묶음의 각 글에 대한 경향
위 결과에서 보면, 2, 4 묶음은 비교적 뚜렷한 경향이 있는데, 1과 3은 아주 눈에 띄지는 않습니다. 그래서, 각 친구묶음이 다른 친구들이 더 좋아하는 글들에도 댓글을 쓰는 경향이 얼마나 되는지 봤습니다. 즉, 자기 취향의 글에 대한 일편단심 충성도(?)라고 볼 수도 있겠죠.
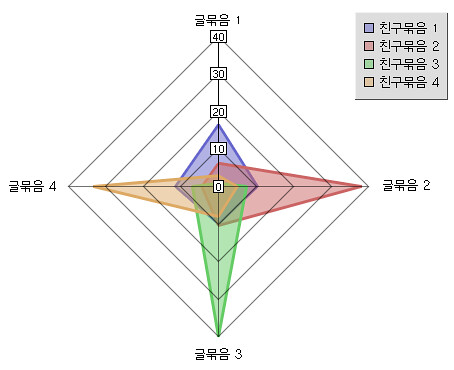
이렇게 보면 뚜렷하게, 첫번째 묶음 (파란색)은 뚜렷한 경향없이 평균적으로 모든 취향의 글에 댓글을 달고, 다른 친구묶음의 친구들은 뚜렷한 취향을 가지고 “책 관련 된 글” 또는 “행사/학술 관련된 글”에만 댓글을 달고 있다는 것을 볼 수 있습니다. (그래프의 수치는 해당 친구묶음 내의 관련 글묶음 댓글 빈도 %) 그리고, 또 특이한 것은 파란색과 초록색은 모두 일상생활 또는 사적인 감정에 대한 글들 취향이었는데, 초록색은 누구나 댓글을 쉽게 다는 파란색 취향에는 오히려 댓글을 더 적게 달았군요. ^^;
정리
대략적으로 가설에서 세웠던 것대로, 적지 않은 친구들이 뚜렷한 자기 취향을 갖고 관심 글에만 댓글을 달고 있다는 것을 확인할 수 있었고요, 이를 토대로 댓글을 단 친구의 구성만 봐도 대략적인 글 내용이나 성향을 파악할 수 있다는 것을 알게 되었습니다.
사실 뭐 누구나 이미 감으로 알고 있는 것이지만.. 그냥… 진짜 그런지 확인해 보고 싶었어요 ^^;;
덧붙임: 여기서는 k-means clustering과 빈도수 샘플링 같은 간단한 것들만 사용했는데, 실제로 이 모델을 제대로 묘사하려면 MCMC EM같은 숨은 확률을 반영할 수 있는 도구를 써야할 것 같습니다.Watch Full Movie Online Streaming Online and Download