예전부터 꼭 해 보고 싶었던 것 중의 하나로 이름 데이터베이스를 구해서
흔한 이름, 여성적 이름, 중성적 이름 등등 같은 것 통계내기가 있었습니다.
요새 주변 사람들 중에 아기를 낳아서 새로 이름 짓는 사람도
많고, 아무래도 이름에서 나오는 느낌의 신비(?)에 접근하고 싶어서! -ㅇ-
그러다가 얼마 전에 이름 데이터베이스를 하나 구했는데, 정보활용 동의를 받은
사이트에 가입한 분들의 정보에서 이름, 성별 2가지만 추출한 것을 받았기 때문에
개인정보보호와 관련된 문제는 심각하지 않을 것 같습니다. 정확한 통계를 위해서는
성별외에도 생년이나 출생지같이 이름에 중대한 영향을 미치는 요소를 파악해서
편향성을 봐야하겠지만, 개인정보의 과다한 사용이 될까 해서 그냥 이름 성별 외에는
사용하지 않기로 결정했습니다. 그 결과 통계에 편향이 있는 것은 눈에 보이지만
편향을 피하기도 힘들고, 신뢰도가 어느 정도 되는지 정확히 통계적인 분석은
불가능했습니다. 따라서, 아래 분석은 그냥 재미로 읽어주시고 과학적인 통계로
이뤄진 것이 아님을 유의해 주세요. 🙂
사용한 데이터셋은 기본적인 오타나 잘못 입력된 것이 명확한 자료들, 깨진 자료들은
수작업으로 제거했고, 결국 80757명 (남자 52640명, 여자 28117명) 데이터로 분석했습니다.
여자 수가 훨씬 적게 샘플링됐기 때문에, 전체적으로 분석에서 비율에 맞춰서 보정하려고
노력했습니다.

성씨별 빈도
기본적으로 성씨별 빈도는 통계청에서도 발표하는 자료이기 때문에
우리 데이터셋이 성씨별로 편향되어 있지 않은지 보기 위해 똑같이 빈도 조사를 해 봤습니다.
그래서 순위를 보면 (한자는 음가기준으로 합산)
| 순위 |
2000년 통계청 |
데이터셋 |
| 1 |
김 (21.6%) |
김 (21.6%) |
| 2 |
이 (14.8%) |
이 (14.8%) |
| 3 |
박 (8.5%) |
박 (8.4%) |
| 4 |
정 (4.9%) |
정 (4.8%) |
| 5 |
최 (4.7%) |
최 (4.7%) |
| 6 |
조 (2.9%) |
조 (2.9%) |
| 7 |
강 (2.5%) |
강 (2.4%) |
| 8 |
윤 (2.1%) |
장 (2.2%) |
| 9 |
장 (2.1%) |
임 (2.1%) |
| 10 |
임 (2.0%) |
윤 (2.1%) |
아주 비슷하게 나온 것이, 장난으로 엉뚱한 이름으로 가입한 경우가 그렇게 많이 포함되어
있지 않고 편향도 그다지 뚜렷한 것은 아니라는 것을 확인할 수 있습니다.
이 다음 통계부터는 성과 이름을 분리해서 쓰기 때문에 2글자 성을 구별할 필요가 있었는데요.
특별히 좋은 방법이 없어서 그냥 일정 빈도 이상의 2글자 성씨로 시작하는 이름을 모두 2글자
성씨로 봤습니다. 즉 “서문교”같은 이름은 서씨인지 서문씨인지 구분할 수 없으므로 그냥 모두
서문씨인 것으로 처리했습니다. (이 조사에서 처리한 2글자 성씨: 남궁, 독고, 동방, 사공, 서문,
선우, 제갈, 황보)
가장 흔한 이름은 무엇일까!
자기 이름이 무척 흔한 분들은 보통 인터넷에 이름 쓸 때도 전혀 거리낌 없이 막 써도
익명이 보장될 정도인데요. 과연 흔한 이름은 어떤 게 있을까 무척 어릴 때 부터 궁금했는데
정량적으로 조사해 봤습니다! 물론 세대별 차이가 있긴 한데, 이번 데이터셋은 이름, 성별 외의
개인정보를 사용하지 않았기 때문에 세대별 편향성 같은 것은 고려하지 않았습니다.
| 1 |
정훈 (0.367%) |
미경 (1.106%) |
| 2 |
성호 (0.350%) |
은주 (1.024%) |
| 3 |
정호 (0.293%) |
미영 (0.942%) |
| 4 |
성진 (0.285%) |
은영 (0.882%) |
| 5 |
성훈 (0.285%) |
경희 (0.850%) |
| 6 |
영수 (0.281%) |
은경 (0.839%) |
| 7 |
상훈 (0.277%) |
정희 (0.825%) |
| 8 |
영호 (0.264%) |
은정 (0.818%) |
| 9 |
준호 (0.262%) |
미숙 (0.804%) |
| 10 |
진호 (0.260%) |
현숙 (0.800%) |
아는 정훈이 미경이가 보통 너댓명 씩은 되시니까 다들 1등은 놀라지 않으실 것 같네요 🙂
그 뒷 순위로는 남자는 재호- 영진 – 상현 – 성환 – 재영 – 영민 – 재훈 – 영준 – 영철 – 성수 등등이고, 여자는 은희 – 현주 – 미정 – 영미 – 현정 – 지영 – 영숙 – 정숙 – 선희 – 은숙 이렇게 나가는데, 둘의 비율 차이가 비교가 안 될 정도입니다. 즉, 여자 이름은 0.2% 이상 이름이 115개나 되는데 남자는 0.2% 이상이 27개 밖에 안 됩니다. 여자 이름이 훨씬 집중적으로 같은 이름이 많이 쓰이고, 남자 이름이 다양성이 높다고 볼 수 있겠습니다. (엔트로피 계산은 생략;;)

이름에 많이 쓰이는 글자는?
이름 전체 말고 각 글자별로 보는 방법도 있겠죠~ 그래서 성별로 어떤 글자가 위치별로 많이 쓰이는지
알아봤습니다.
| 순위 |
남자 앞 |
남자 뒤 |
여자 앞 |
여자 뒤 |
| 1 |
성 5.56% |
호 5.42% |
미 8.34% |
희 10.04% |
| 2 |
영 5.09% |
수 4.67% |
은 7.66% |
숙 9.31% |
| 3 |
상 4.30% |
석 3.32% |
정 6.12% |
영 6.90% |
| 4 |
재 4.19% |
철 3.30% |
영 5.64% |
정 6.15% |
| 5 |
종 4.12% |
훈 3.13% |
경 4.81% |
경 5.47% |
| 6 |
정 4.03% |
현 3.12% |
현 4.51% |
미 5.29% |
| 7 |
동 3.07% |
진 2.92% |
선 3.89% |
자 4.81% |
| 8 |
용 3.00% |
영 2.58% |
혜 3.83% |
순 4.60% |
| 9 |
승 2.79% |
환 2.55% |
지 3.72% |
선 3.61% |
| 10 |
경 2.68% |
식 2.54% |
수 2.77% |
주 3.49% |
역시 여자 이름이 흔히 쓰는 글자가 좀 더 집중되어 있는데, 보통 한국인의 평균 얼굴 만들듯이
대충 아무렇게나 상관관계 없이 뽑았을 때 가장 흔해 보이는 이름은 성호, 미희 가 되겠습니다.
성별 구분을 하지 않고 그냥 뽑으면 영희가 가장 대표적인 이름이 됩니다. 🙂
제 이름은 여자 앞글자에서 8등, 남자 뒷글자에서 10등 했군요;;;;
도무지 여자인지 남자인지 알 수 없는 이름은!
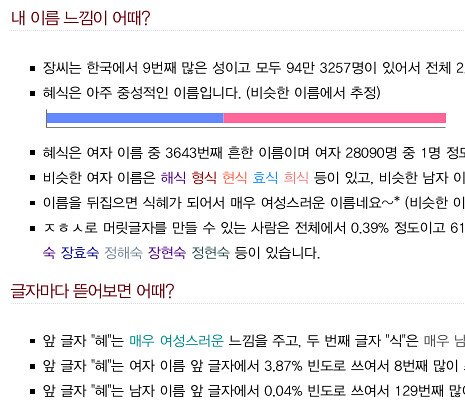
종종 중성적 매력이 있는 이름이 있죠. “정민”이라던지.. 양쪽에서 모두 많이 쓰여서 이름만 봐서는
설렐지 안 설렐지 결정도 못할 무서운 그런 이름! 흐흐. 그래서 양쪽에서 모두 많이 쓰이는 이름들을
찾아 봤습니다. 성별 편향은 여성내비율 / (남성내비율 + 여성내비율) 로 계산했으므로
0에 가까운 값이 나오면 남자 이름에서 압도적으로 많이 쓰이는 것이고 1에 가까우면 여성 편향이
있는 게 됩니다. 샘플이 적은 이름들은 비율이 잘못 계산될 수 있기 때문에 최소 0.05% 이상 있는
이름에 대해서만 조사했습니다.
|
|
경진 0.492 태희 0.494 기정 0.495 정윤 0.498 희원 0.4996 진 0.531 정민 0.532 윤영 0.542 주현 0.547 세영 0.555 |
태희는 당연히 여자 아닌가 생각했더니, 거의 완벽한 중성적 이름이군요. -ㅁ-;
저도 저런 이름 있었으면 무척 좋았을텐데 아쉽네요. 제 이름은 남자반 여자반 갈라놓은
남녀공학 학교같은 분위기라서 –;;
그런데, 성별 편향을 조사하면서 잘 살펴보면 0.5 경계선 주변의 이름이 그다지 많지 않다는
것을 알 수 있었습니다. 그래서 편향값의 분포를 히스토그램으로 그려 봤는데 진짜 확실하게
드러납니다.

여성쪽이 압도적으로 확 올라가 버리는 것은 이름이 아무래도 집중되는 경향도 있긴 하지만,
여자가 남자이름을 쓰는 경우가 남자가 여자이름을 쓰는 경우에 비해서 훨씬 많은 것이 주요
원인인 것 같군요.
남자/여자 이름에 각각 많은 글자?
전체적인 빈도 뿐만 아니라, 어떤 특정 글자가 전체적인 느낌을 압도해서 남자로 만들어버린다거나
여자로 만들어버리는 글자들이 제법 있는데요. 예를 들어서 “철”이나 뒷 글자가 “국”인 경우에는
웬만한 글자가지고는 여자이름을 만들기가 어렵고, 앞 글자가 “미”나 뒷 글자가 “숙”인 경우에는
남자 이름을 만들기가 쉽지가 않습니다. 그래서 한 번 글자별 성별 편향을 조사해 봤습니다.
편향성은 마찬가지로 아까와 같이 0과 가까우면 남자, 1과 가까우면 여자입니다.
| 순위 |
남자 앞글자 |
남자 뒷글자 |
여자 앞글자 |
여자뒷글자 |
| 1 |
왕 (0.0) |
황 (0.0) |
미 (0.9954) |
애 (1.0) |
| 2 |
웅 (0.0) |
율 (0.0) |
애 (0.9908) |
분 (1.0) |
| 3 |
범 (0.0184) |
률 (0.0) |
난 (0.9905) |
녀 (1.0) |
| 4 |
철 (0.0268) |
술 (0.0) |
혜 (0.9892) |
름 (1.0) |
| 5 |
대 (0.0341) |
걸 (0.0) |
숙 (0.9840) |
자 (0.9996) |
| 6 |
익 (0.0352) |
탁 (0.0) |
소 (0.9824) |
란 (0.9987) |
| 7 |
중 (0.0538) |
백 (0.0) |
분 (0.9771) |
미 (0.9986) |
| 8 |
낙 (0.0612) |
돈 (0.0) |
아 (0.9662) |
혜 (0.9983) |
| 9 |
택 (0.0630) |
룡 (0.0) |
매 (0.9630) |
임 (0.9981) |
| 10 |
권 (0.0738) |
건 (0.0) |
말 (0.9571) |
라 (0.9969) |
| 상위 25 평균 |
0.0727 |
0.0069 |
0.9337 |
0.9848 |
역시 뭔가 성별을 치명적으로 결정해버릴 수 있는 글자들이 많이 보이는 것 같군요. 🙂
그런데, 뒷 글자가 앞 글자에 비해서 편향이 훨씬 심한 것을 볼 수 있는데, 그래서
남녀 데이터를 모두 합쳐서 앞/뒤의 각각의 표준편차를 구해봤는데 각각 0.31, 0.38로
차이가 제법 나는군요. 앞 글자보다는 뒷 글자가 전체 성별 느낌을 결정하는데 중요한
역할을 하는게 아닌가 싶습니다.
앞 뒤 위치에 따라서 성별이 다른 글자
어떤 글자들은 앞에 오면 남자이름에 주로 쓰이지만, 뒤에 갈 때는 여자이름에 쓰이는 경우가
있는데요, 이런 게 어떤게 있는지 한 번 찾아봤습니다. (편향은 앞의 설명과 마찬가지로 계산했습니다.)
| 글자 |
앞글자 편향 |
뒷글자 편향 |
| 보 |
0.747 (여) |
0.084 (남) |
| 수 |
0.725 (여) |
0.093 (남) |
| 복 |
0.777 (여) |
0.239 (남) |
| 서 |
0.625 (여) |
0.087 (남) |
| 행 |
0.604 (여) |
0.128 (남) |
예를 들어, “보”가 앞에 오면 여자 이름인데, 뒤에 오면 남자인 경향이 훨씬 높다는 것이죠.
그런데 신기하게도 편향이 차이나는 것 상위 13개가 모두 앞 글자에서 여자/뒷 글자에서
남자이고, 처음으로 뒷 글자에서 더욱 여성스러워 지는 것은 “이” (0.57 -> 0.92),
“자” (0.65 -> 0.99) 입니다.
성별을 진짜로 확! 바꿔버리는 글자
앞에서는 그냥 전체적으로 한 성별에서 많이 나오는 글자들을 조사했는데요. 이번에는
원래는 여성성이 있는 글자에 다른 글자가 붙어서 남성 이름으로 바꿔버린다던지 완전히
반대로 바꿔버리는 글자들이 있는지 조사해 봤습니다.
| 순위 |
남성 앞글자 편향조절 |
여성 앞글자 편향조절 |
남성 뒷글자 편향조절 |
여성 뒷글자 편향조절 |
| 1 |
철 (0.703) |
슬 (-0.672) |
호 (0.549) |
아 (-0.572) |
| 2 |
대 (0.576) |
미 (-0.642) |
석 (0.522) |
이 (-0.519) |
| 3 |
요 (0.546) |
예 (-0.491) |
규 (0.494) |
미 (-0.486) |
| 4 |
충 (0.490) |
혜 (-0.441) |
상 (0.480) |
실 (-0.485) |
| 5 |
치 (0.486) |
소 (-0.433) |
준 (0.468) |
숙 (-0.484) |
| 6 |
창 (0.468) |
은 (-0.433) |
용 (0.460) |
순 (-0.435) |
| 7 |
형 (0.455) |
금 (-0.342) |
식 (0.451) |
림 (-0.428) |
| 8 |
동 (0.448) |
옥 (-0.329) |
찬 (0.442) |
경 (-0.422) |
| 9 |
용 (0.445) |
여 (-0.315) |
필 (0.437) |
은 (-0.421) |
| 10 |
병 (0.444) |
지 (-0.311) |
한 (0.436) |
례 (-0.419) |
므흐흐. 역시 단순 빈도 조사를 한 앞 것보다 좀 더 결정적인 글자들이 강조되었는데요.
제 이름은 앞 글자에서 -0.441, 뒷 글자가 0.451 해서 아슬아슬하게 남자 이름이 되었군요!
-O-;
한 위치에만 압도적으로 많이 쓰이는 글자
각 성별 안에서도 한 자리에만 많이 나오는 글자가 있는데, 뭐가 있나 조사해 봤습니다.
| 순위 |
남자 앞글자 |
남자 뒷글자 |
여자 앞글자 |
여자 뒷글자 |
| 1 |
자 (52/1) |
식 (1/1339) |
세 (135/1) |
실 (1/160) |
| 2 |
병 (1394/31) |
섭 (3/798) |
소 (360/4) |
심 (2/162) |
| 3 |
지 (498/13) |
곤 (1/240) |
계 (59/1) |
례 (3/167) |
| 4 |
여 (36/1) |
엽 (1/152) |
보 (160/3) |
랑 (1/29) |
| 5 |
시 (108/3) |
열 (7/555) |
유 (314/7) |
자 (52/1353) |
-식, -실, -례 는 자주 보지만 식-, 실-, 례-는 좀처럼 보기 힘든 것 같은 게 위의 표에서
표현되어 있는데, 전체를 조사해 보면 반 정도 글자는 앞 뒷 글자 구분이 있고,
반 정도는 앞 뒤에서 모두 사용되는군요.
한글 자모별 편향
한글은 분해해서 자모의 느낌도 볼 수 있으니까, 각 자모별 조사도 해 봤습니다~
전체 자료는 표시하기에 너무 많아서 몇 가지 주요 자모만..
|
ㄱ |
ㄷ |
ㅁ |
ㅅ |
ㅇ |
ㅈ |
ㅊ |
ㅌ |
ㅎ |
| 남자 초성 (앞) |
11.0 |
6.3 |
4.0 |
18.2 |
17.1 |
19.8 |
5.0 |
2.6 |
10.1 |
| 남자 초성 (뒤) |
12.4 |
2.3 |
4.4 |
18.4 |
18.5 |
9.6 |
5.1 |
2.0 |
21.2 |
| 여자 초성 (앞) |
8.4 |
0.9 |
13.4 |
17.2 |
24.8 |
15.6 |
1.3 |
0.4 |
14.5 |
| 여자 초성 (뒤) |
6.4 |
0.5 |
6.3 |
20.5 |
22.8 |
18.9 |
0.2 |
0.0 |
17.5 |
|
ㅏ |
ㅐ |
ㅓ |
ㅕ |
ㅗ |
ㅘ |
ㅛ |
ㅜ |
ㅡ |
ㅢ |
ㅣ |
| 남자 중성 (앞) |
11.1 |
9.3 |
14.8 |
16.8 |
11.1 |
2.8 |
3.8 |
8.2 |
4.6 |
1.3 |
11.0 |
| 남자 중성 (뒤) |
5.5 |
4.7 |
15.1 |
10.6 |
11.3 |
4.3 |
2.6 |
20.7 |
2.6 |
1.7 |
13.9 |
| 여자 중성 (앞) |
4.5 |
3.0 |
13.2 |
20.0 |
5.8 |
0.9 |
1.5 |
9.3 |
10.1 |
2.1 |
19.7 |
| 여자 중성 (뒤) |
11.1 |
2.6 |
10.9 |
18.2 |
4.0 |
2.9 |
0.3 |
19.2 |
2.1 |
10.2 |
14.7 |
|
없음 |
ㄱ |
ㄴ |
ㄹ |
ㅁ |
ㅂ |
ㅇ |
ㅍ |
| 남자 종성 (앞) |
23.9 |
3.6 |
19.2 |
2.4 |
1.5 |
0.2 |
49.2 |
0.0 |
| 남자 종성 (뒤) |
28.9 |
13.0 |
31.4 |
8.1 |
2.1 |
2.1 |
14.4 |
0.0 |
| 여자 종성 (앞) |
34.8 |
3.3 |
31.3 |
1.0 |
2.0 |
0.1 |
27.6 |
0.0 |
| 여자 종성 (뒤) |
38.1 |
13.6 |
23.0 |
1.0 |
3.3 |
0.2 |
20.7 |
0.0 |
가만 보고 있으면, 어감하고 직결되는 부분이 몇 군데가 확 눈에 띄는데요, 여자 이름에
받침이 없는 경우가 훨씬 많고, 뒷글자에 훨씬 많이 나오는 종성 같은 것들이 뚜렷하군요.
(분석할 것은 많지만 지면 상 생략 -ㅇ-) 재미있는 것은 남자 중 거의 절반이
이름 앞글자가 ㅇ 받침이네요. +_+
성과 연결된 이름
종종 이름 중에 한가지 성씨하고 유독 잘 어울리는 이름이 있습니다.
예를 들어 한아름, 조아라, 정다운 이런 이름은 다른 성보다 한 성에 보통 집중되어 있죠.
그래서 그런 게 어떤게 있나 조사해 봤습니다. (괄호 안의 수치는 성의 빈도에 대한
해당 이름 내의 성의 빈도차)
여자이름
정다운 (21배), 조아라 (17.9배), 한송희 (14배), 한아름 (13.4배), 한송이 (11.5배),
고은선 (9.4배), 안소희 (8.4배), 조한나 (8.3배)
남자이름
남궁원 (268배), 백운봉 (125배), 심현보 (107배), 구정모 (79배), 허근 (69.7배), 홍준표 (59.4배),
홍광표 (55.4배), 권혁성 (53배), 홍원표 (52배), 권오성 (47.7배), 권대혁 (45.4배), 허욱 (39.6배)
여자이름은 대부분 연결된 글자들이 뜻하는 다른 단어들이 영향을 많이 주었는데,
남자이름은 돌림자와 관련된 것이 매우 많습니다. 즉, 홍씨와 권씨가 압도적으로 상위 빈도를
모두 차지했는데, 그 이유를 연구실 동료인 홍모군에게 문의한 결과, 홍씨가 넘어온 것이 조선대라서
얼마 되지 않다보니 항렬자가 상당히 같은 연대에서 많이 동기화되어 있다고 하는군요.
그래서 그냥 위치별로도 따로 조사를 해 봤는데, 따로 한 것과 큰 차이는 없어서 이름을 분해한 글자를 기준으로 성과의 상관관계를 봤습니다. (성-이름글자 순서)
여자이름
여-운 (49.4배), 권-혁 (36.1배), 민-홍 (17배), 백-설 (13.2배), 한-름 (13.1배), 남-우 (11.9배)
남자이름
구-본 (246.9배), 연-흠 (221배), 구-자 (141.5배), 인-치 (55.8배), 연-제 (42.1배), 구-회 (35배),
홍-표 (32.4배), 윤-여 (31.5배), 추-엽 (30.5배), 성-낙 (26.9배), 심-보 (20.8배), 곽-노 (19.9배),
권-오 (18.3배), 성-백 (17.9배), 허-행 (15배), 구-모 (14.7배), 임-채 (12배), 원-유 (11.9배)
주로 대부분 돌림자와 관련된 것을 알 수 있는데, 그동안 이상하게 한 성씨에서 한 글자를 많이
봤다 싶은 것들이 골고루 나와있네요. 🙂
머릿글자가 겹치는 이름
이름을 대충 숨겨서 쓰려고 ㅇㅁㅂ 같은 방법을 많이 쓰는데, 이렇게 쓰면 과연 겹치는 사람이
얼마나 될지 궁금해서 한 번 찾아 봤습니다. 머릿글자가 ㅇㅁㅂ인 사람은 8만명 중 6명으로
0.000075 확률이라서 일부러 누구 찍어서 말하는 게 아니라고 말하기 매우 힘든 수준이라고
볼 수 있겠죠; 그럼 과연 가장 많이 겹치는, 머릿글자만 따도 이미 익명성이 보장되는 것은
어떤 게 있을까요!
| 머릿글자 |
비율 |
예시 |
| ㅇㅈㅎ |
1.50% |
안정환 안재현 오지호 유정현 엄지혜 임지훈 |
| ㅇㅈㅇ |
1.34% |
안재욱 이재오 양진영 오종원 유지연 윤재열 |
| ㄱㅈㅎ |
1.30% |
강종훈 고정환 구자현 권재혁 김정현 김진형 |
| ㅇㅅㅇ |
1.26% |
안상우 양소영 유수연 윤선영 이승엽 임순옥 |
| ㄱㅇㅅ |
1.20% |
강은숙 공영섭 곽영수 금윤섭 김연실 김은수 |
위 이름 쓰시는 분들은 좋겠어요~ 머릿글자가 익명이라.. ^^;
마지막으로..
여러가지 이름에 대한 통계를 해 봤는데, 그동안 피상적으로 느꼈던 것을 정량적으로
확인해 볼 수 있는 기회가 됐습니다. 이름과 성별 밖에 없는 자료이기는 하지만,
그래도 혹시 있을 수 있는 오용을 막기 위해 위에서 공개된 자료 외에는 추가로 공개하지는
않을 예정입니다. 다음에는 여러 가지 기계학습 기법들을 이용한 이름 -> 성별 판단 루틴들을
만들어서 시험해 보는 글을 언젠가는 한 번 써 보려고 아이디어를 정리하고 있습니다. ^^;